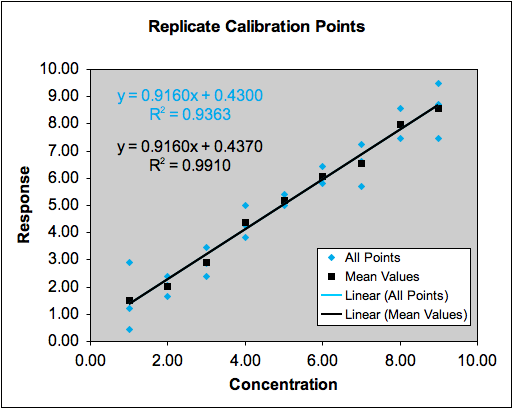
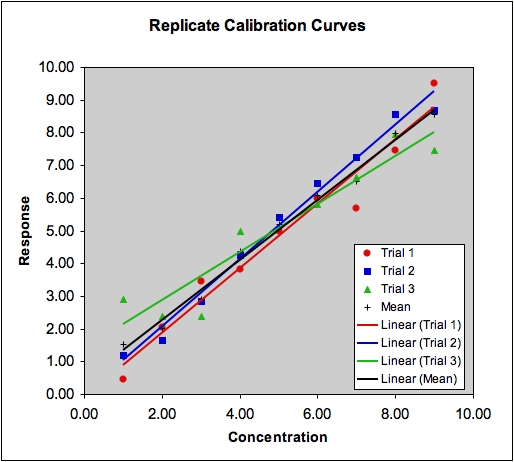
Dealing with Outliers:
A common problem encountered in instrument calibration is when one or two measurements are clearly ‘off’ – that is, they lie some distance from the regression line when all the other calibration points are close to it. Typically, this is the result of a gross error on the part of the operator, either when preparing the solution or performing the measurement.
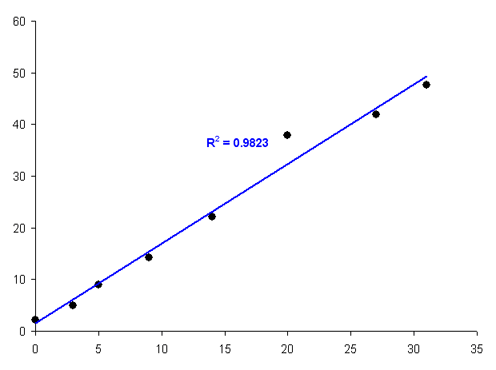
Consider for example the graph below: the value at xi = 20 is possibly an outlier and skewing the regression line. Can we discard it? A starting point is to calculate the regression residuals and examine them individually. Note that the residual for the suspect point is noticeably different from the others:
| +0.6 |
| -1.1 |
| -0.2 |
| -1.1 |
| -0.9 |
| +5.6 |
| -1.2 |
| -1.7 |
Residuals for the calibration plot shown, with a single outlying value
Such a point that lies “far away” from the expected value, i.e. has a large regression residual, is called an outlier. Such outliers can easily skew your regression line. However, they can also reveal information about an incomplete regression, or the requirement for more a complex regression model. It is therefore important to know how to deal with such values.
One way of dealing with outliers is to use either weighted linear regression* (in which the standard deviations for replicate determinations of each calibration point are used as “weights” within the analysis), or robust techniques which use median, rather than mean, values. Such methods are beyond the scope of this tutorial, but can be found in the relevant texts. An alternative approach is to make use of statistical tests developed for identifying outliers amongst replicate values, such as Grubb’s test and Dixon’s Quotient (Q) test.
* A recent article has questioned the use of weighted least-squares regression in calibration. See J. Tellinghuisen, Analyst, 2007, 132, 536-543. (DOI: 10.1039/b701696d).